
Traffic Splitting with Audiences and Variations
Deploy models with traffic splitting and A/B testing using Audiences and Variations
JFrog ML provides multiple ways to split traffic and run A/B tests using Audiences and Variations. Using JFrog ML, you can segment traffic, compare different variations, and make data-driven decisions to enhance the performance of your models.
Segmenting traffic with Audiences
Audiences are a powerful tool for categorizing traffic on predefined client-side metadata conditions. Configured at the JFrog ML Account level, they apply to all real-time models within the Account.
By default, requests that do not meet any specific Audience criteria are routed to the fallback Audience.
Note: Audience details must be included in the metadata or header fields at each inference request.
Creating an Audience
Audiences are created using YAML files and managed via the Qwak CLI.
Below is an example of an Audience that categorizes users from New York aged between 10 and 30
The first condition matches the location field to be new-york. This match has to be exact, it's not a regex.
The second condition is binary, where the age key is in the range specified with first_operand and second_operand.
api_version: v1
spec:
audiences:
- name: New-York
description: Users from New York aged 10-30
conditions:
unary:
- key: location
operator: UNARY_OPERATOR_TYPE_EXACT_MATCH
operand: new-york
binary:
- key: age
operator: BINARY_OPERATOR_TYPE_RANGE_MATCH
first_operand: 10
second_operand: 30Each audience definition must include:
- Name: A display name of the audience used on the JFrog ML platform UI.
- Description: A general description of the audience.
- Conditions: A list of conditions with an AND operand between them.
Defining Conditions
The following condition types are available when creating an audience:
Unary operators
UNARY_OPERATOR_TYPE_EXACT_MATCH: Matches an exact value.UNARY_OPERATOR_TYPE_SAFE_REGEX_MATCH: Matches using a regular expression.UNARY_OPERATOR_TYPE_PRESENT_MATCH: Checks for the presence of a key.UNARY_OPERATOR_TYPE_PREFIX_MATCH: Matches values that start with a specified prefix.UNARY_OPERATOR_TYPE_SUFFIX_MATCH: Matches values that end with a specified suffix.UNARY_OPERATOR_TYPE_CONTAINS_MATCH: Matches values containing a specified substring.
Binary operator
BINARY_OPERATOR_TYPE_RANGE_MATCH: Checks if a value falls within a specified range.
Registering and managing Audiences
Register an audience from a config file
Apply an audience configuration using a CLI command:
qwak audiences create -f <path_of_audience_config.yaml>List all existing audiences
Returns a list of audience ids and names.
qwak audiences listRetrieve the details of a specific audience
To get the audience-id use the qwak audiences list command first, to retrieve all audiences with their IDs.
qwak audiences get --audience-id <audience_id>
TipFor a full list of available options and parameters, use the command
qwak audiences --help.
Directing traffic to Audiences
In the following examples, we demonstrate how to route requests to specific Audiences.
Using the Python Client
from qwak_inference import RealTimeClient
model_id = <your_model_id>
feature_vector = <...>
metadata = {"location": "new-york", "age": 25}
client = RealTimeClient(model_id=model_id)
client.predict(feature_vector, metadata=metadata)Using REST calls
curl --location --request POST 'https://models.<your_env>.qwak.ai/v1/1_hour_model/predict' \
--header 'Content-Type: application/json' \
--header 'location: new-york' \
--header 'age: 25' \
--header 'Authorization: Bearer <Auth Token>' \
--data '{
"columns": ["feature_1", "feature_2"],
"index": [0],
"data": [[0.0, 0.0]]
}'Note: Audience information is not stored in the JFrog ML Analytics Lake. This means that audience information of requests cannot be tracked.
Splitting traffic with Variations
Variations are used for traffic splitting, operating above the Audience level. They have the following key characteristics:
- Each Variation is linked to a specific model Build.
- Variations always draw traffic from an Audience, so creating an Audience is required before using Variations.
- They can allocate traffic by percentage from various audiences or between different Builds, enabling effective A/B testing. Variations can be designated as Shadow Variations, which replicate a percentage of live traffic to other Builds for testing purposes.
- Each Variation can direct traffic to only one deployed Build at a time.
- The Variation assigned to a request is recorded in Analytics under the column
variation_name.
Assigning traffic to Variations
When deploying a model with multiple variations, audiences are assigned to specific variations, including the fallback audience and a fallback variation.
When distributing traffic from an audience to multiple variations, the total percentage allocated must equal 100% of that audience's traffic.
The only exception is the Shadow Variation, which can receive less than 100% of live traffic.
The currently deployed Variations appear under Traffic Control section in the model overview:
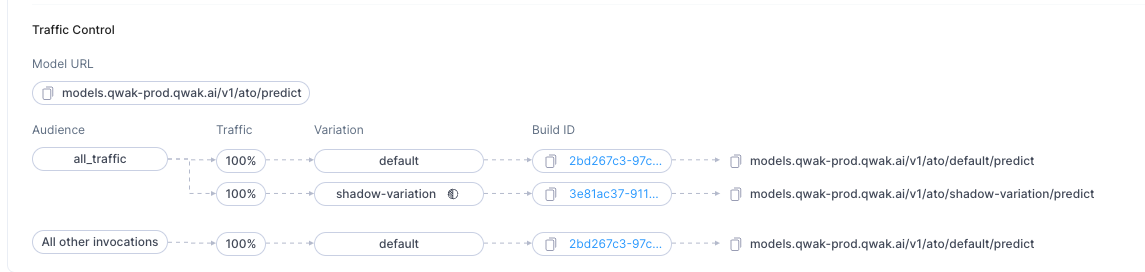
Fallback Variation: Receives traffic that doesn't match any audience.
Connecting Audiences to Variations: Audiences can be linked to one or more variations, with traffic between variations distributed randomly based on defined percentages.
To modify traffic configuration:
- Edit the deployment of the desired build.
- Adjust the percentage of traffic for each variation.
Enabling Variations with the default Audience
default AudienceIn certain scenarios, you may not require the traditional traffic categorization provided by Audience conditions. For such cases, JFrog ML offers support for a default Audience, which lacks conditions but enables the utilization of Variations for all requests.
Below is an example of configuring the default Audience to enable Variations:
api_version: v1
spec:
audiences:
- name: default
description: All trafficTo register this Audience configuration, please refer to the Audiences section above.
Undeploying a multi-Variation Realtime Model
Once you have more than one build deployed, when you undeploy an existing build, you must specify how to split the traffic after the undeployment.
Undeploying models using the UI
To undeploy a variation:
- In the build view, click the options icon next to a deployed build and select Undeploy.
- Redistribute the traffic between the remaining variations and then click Undeploy.
Undeploying models using the CLI
To undeploy a model with variation from the CLI, run the following command:
qwak models undeploy \
--model-id <model-id> \
--variation-name <variation-name> \
--from-file <config-file-path>With a configuration file as follows:
realtime:
variation_name: <The variation name being undeployed>
audiences:
- id: <remaining audience id>
routes:
- variation_name: <other existing variation>
weight: 80
shadow: false
- variation_name: <other existing variation 2>
weight: 20
shadow: false
fallback_variation: <other existing variation>If you use --variation-name in the CLI command, you don't have to pass the variation_name in the configuration file.
When undeploying from 2 variations to one, you don't have to pass any variation-related data -all the traffic will pass to the remaining variation.
NoteBy default the undeploy command is executed asynchronously, which means that the command does not wait for the undeployment to complete.
To execute the command in sync, use the
--syncflag.
Updated 11 months ago