
Reusing Trained Artifacts
Introduction
When training in the build stage of the Build pipeline, sometimes we'd like to iterate on different parts of the model logic, without going through a training iteration. For example we have a training iteration that takes a significant amount of time and instead of going thorough this again with each code iteration, we can just skip this phase and simply load the trained artifact from previous model Builds.
Key Concepts
- Build Types: Differentiating between build jobs created for training or deployment (or both).
- Model Registry: Using Qwak's Model Registry to log and retrieve trained artifacts.
- Build Tagging: Tagging builds for easy identification and retrieval.
- Model Initialization: Leveraging the
initialize_model()method to load pre-trained models.
Implementation Steps
First, we'll add a flag as an environment variable to distinguish between training and deployment builds.
class XGBoostModel(QwakModel):
def __init__(self):
self.model = XGBClassifier()
self.job_type = os.environ.get('JOB_TYPE', 'deploy')In the build() method, we'll save the trained model and log it to the Qwak Model Registry.
# Global variables
LOCAL_MODEL_FILEPATH = 'xgboost_model.pkl'
MODEL_ARTIFACT_TAG = 'xgboost_model'
TRAINED_MODEL_TAG = 'training'
def build(self):
# ... (training code) ...
# Save the trained model
with open(LOCAL_MODEL_FILEPATH, 'wb') as file:
pickle.dump(self.model, file)
# Log the trained artifact
qwak.log_file(from_path=LOCAL_MODEL_FILEPATH, tag=MODEL_ARTIFACT_TAG)After a successful training build, tag it in the Qwak UI:
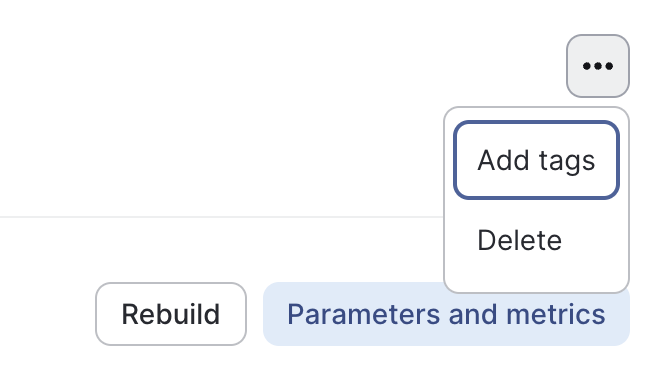
- Navigate to the individual Build
- Click on the three dots in the upper-right corner
- Select "Add Tags"
- Add a tag called
training
Use the initialize_model() method to load the pre-trained model during deployment:
def initialize_model(self):
qwak_client = qwak.QwakClient()
qwak_model_id = os.getenv('QWAK_MODEL_ID')
# Fetch trained builds
trained_builds = qwak_client.get_builds_by_tags(
model_id=qwak_model_id,
tags=[TRAINED_MODEL_TAG]
)
if not trained_builds:
raise ValueError(f"No trained builds found for model ID: {qwak_model_id}")
# Get the latest trained build ID
latest_trained_build_id = trained_builds[0].build_id
# Load the model file
qwak.load_file(
to_path=LOCAL_MODEL_FILEPATH,
tag=MODEL_ARTIFACT_TAG,
model_id=qwak_model_id,
build_id=latest_trained_build_id
)
# Load the model into memory
with open(LOCAL_MODEL_FILEPATH, 'rb') as file:
self.model = pickle.load(file)Complete QwakModel Class
QwakModel ClassHere's how the complete XGBoostModel class might look:
class XGBoostModel(QwakModel):
def __init__(self):
self.model = XGBClassifier()
self.job_type = os.environ.get('JOB_TYPE', 'deploy')
def build(self):
if self.job_type == 'train':
# ... (training code) ...
with open(LOCAL_MODEL_FILEPATH, 'wb') as file:
pickle.dump(self.model, file)
qwak.log_file(from_path=LOCAL_MODEL_FILEPATH, tag=MODEL_ARTIFACT_TAG)
def initialize_model(self):
if self.job_type == 'deploy':
# ... (model loading code from step 4) ...
@qwak.api()
def predict(self, df):
# ... (prediction code) ...
return pd.DataFrame(predictions, columns=['Score'])Conclusion
By implementing these advanced patterns, you can significantly speed up your model iteration process. This approach allows you to load pre-trained models for deployment or quick testing, while still maintaining the ability to perform full training when necessary.
Updated 7 months ago