
Streaming Deployments
Connect your models with Kafka streams to perform real-time predictions.
Introduction
Streaming deployments let you easily connect Kafka streams with your models to perform real-time inference.
Using streaming deployments can be useful for processing large amounts of distributed data to avoiding complex triggering and scheduling architectures as fresh data arrives. A streaming deployment will consume messages from a Kafka topic and produce predictions into a Kafka topic of your choice.
Streaming use cases
Consider using streaming deployments in the following cases:
- Event-driven applications: Respond in real-time to specific events or triggers.
- Real-time decision-making: Process data as it arrives in time-sensitive systems.
- Scalable processing: Process large data volumes from multiple sources and ensure efficient data handling.
Deploying streaming models
To use streaming inference on JFrog ML, use the following examples:
Deploying streaming models via UI
Deploying a streaming model on JFrog ML is simple, just a few clicks and your model is up and running.
- Build a new model
- Click Deploy and choose Streaming
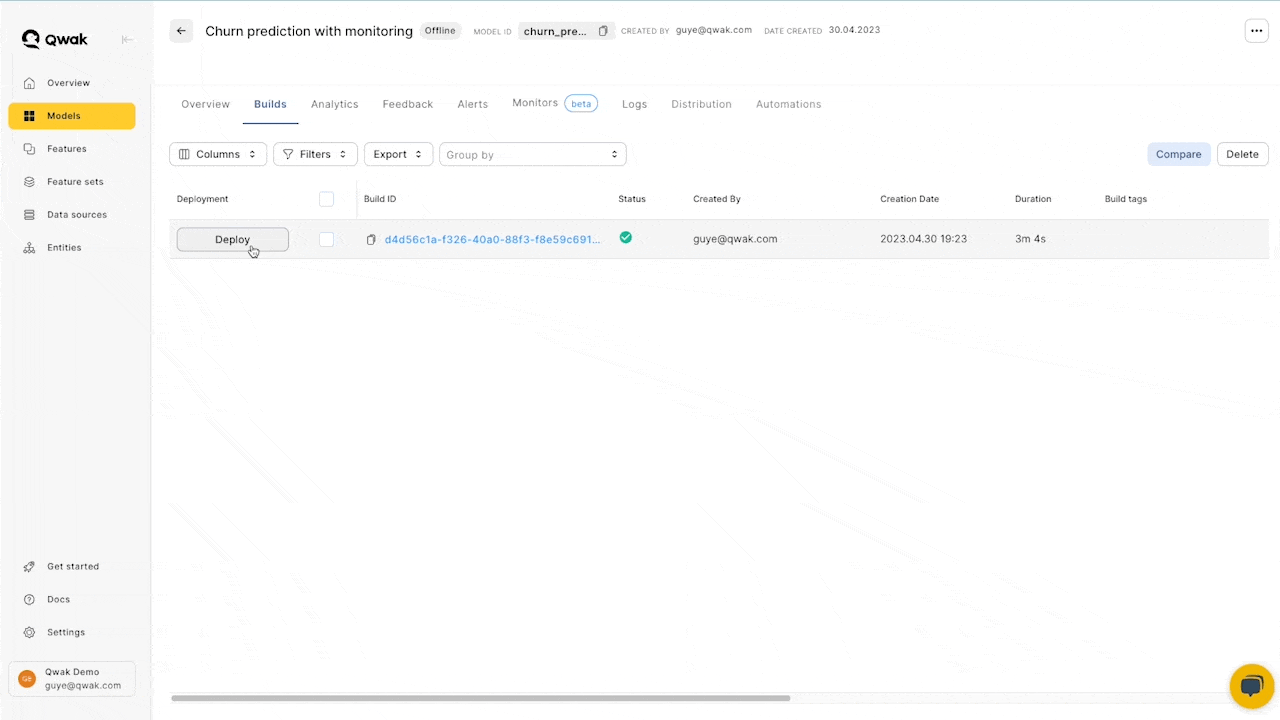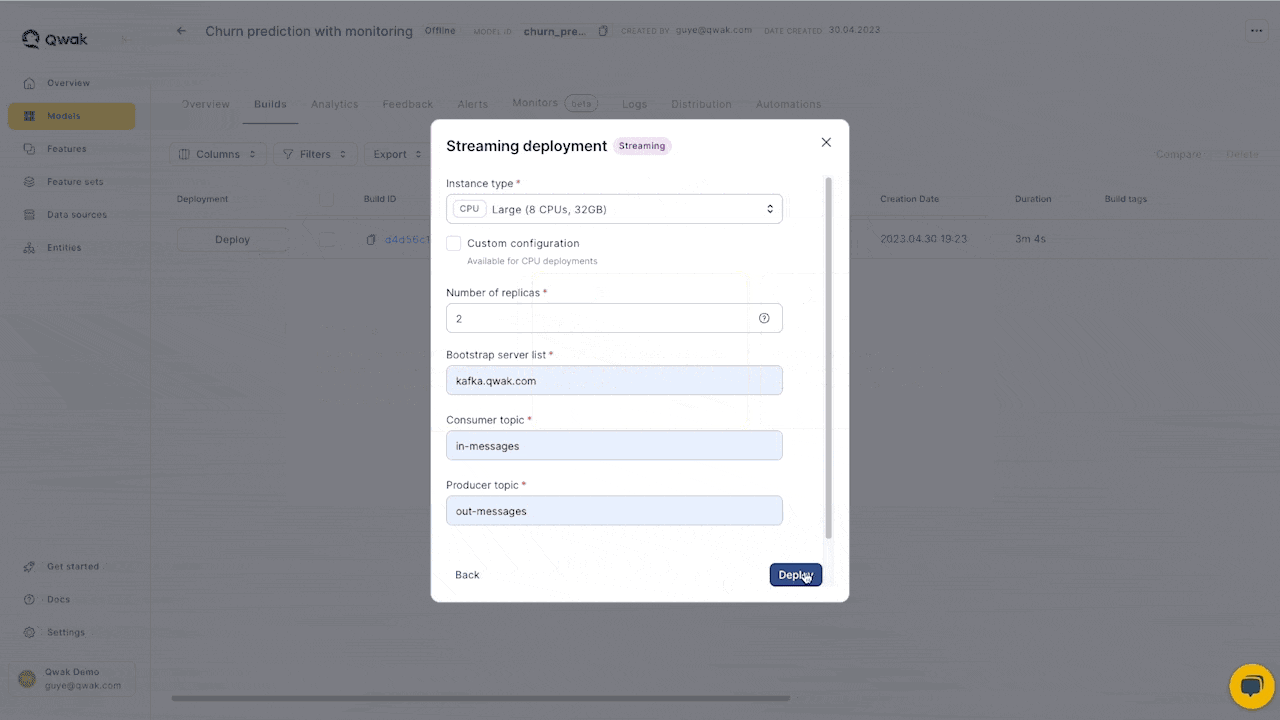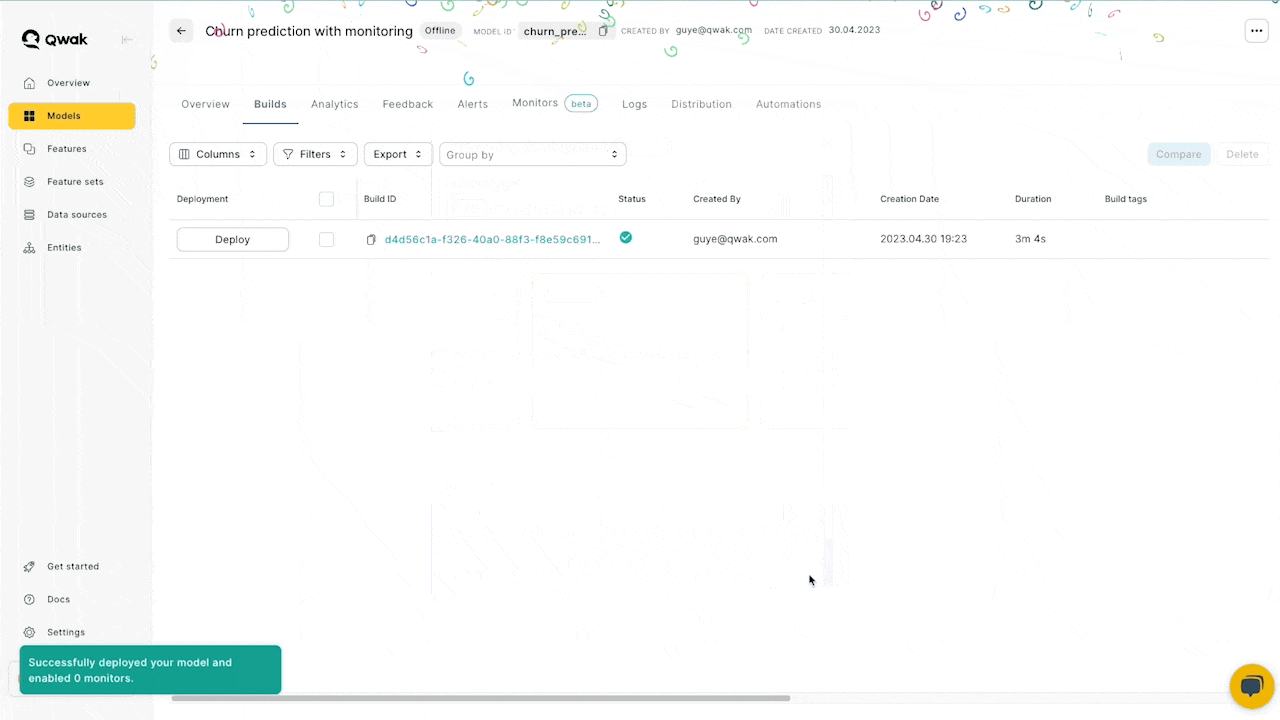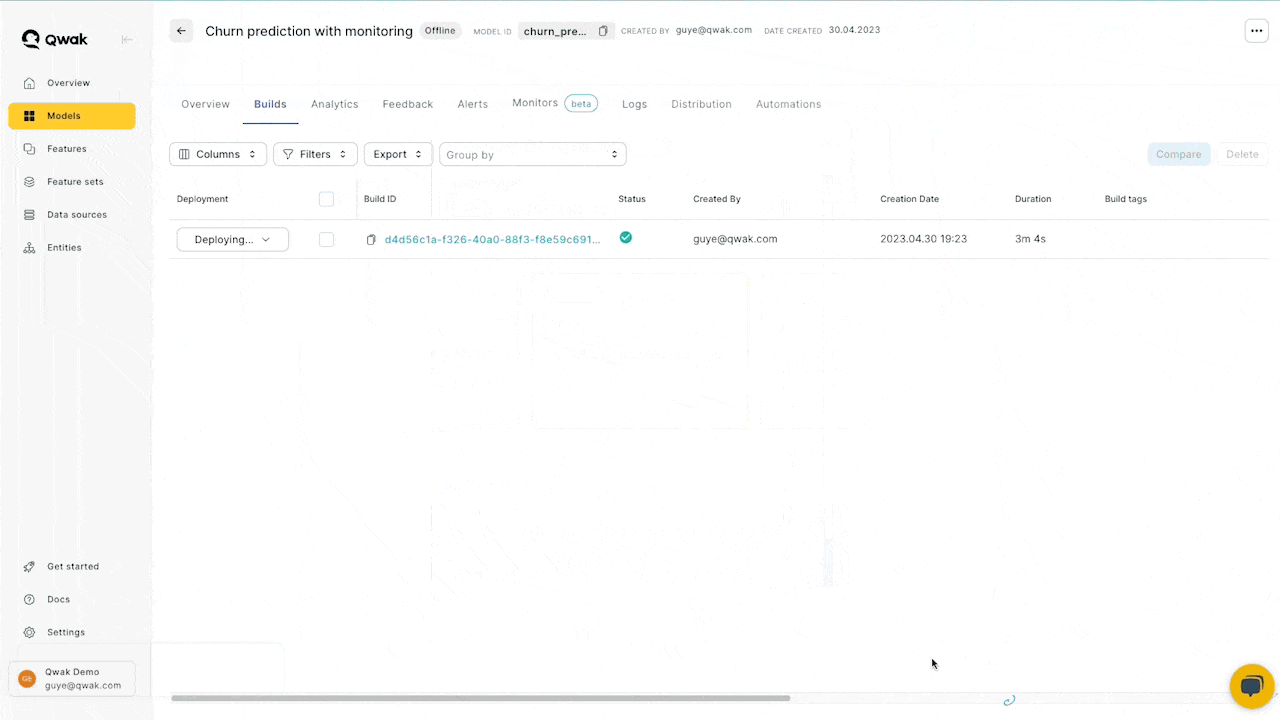
- Select the instance type and configure the Kafka server and topics
- Click deploy and your model will be live!
Deploying streaming models via CLI
To use this example, replace --model-id with your model ID on JFrog ML.
# Deploy a FLAN-T5 streaming model on 2 A10.XL on-demand instances
qwak models deploy stream \
--model-id "flan-t5" \
--build-id "0511ffa9-986e-4fd9-ae29-515269af5bac" \
--instance "gpu.a10.xl" \
--replicas 2 \
--purchase-option "on-demand" \ # Use only on demand instances for executors
--consumer-bootstrap-server <bootstrap-server> \
--consumer-topic <consumer-topic-name> \
--producer-bootstrap-server <bootstrap-server> \
--producer-topic <producder-topic-name> # Deploy a churn streaming model on 2 small instances
qwak models deploy stream \
--model-id "stream-churn-model" \
--build-id "d4d56c1a-f326-40a0-88f3-f8e59c691a3e" \
--instance "small" \
--replicas 2 \
--consumer-bootstrap-server "10.0.0.8" \
--consumer-topic "model-input-topic" \
--producer-bootstrap-server "10.0.0.9" \
--producer-topic "model-output-topic" Configuring streaming models via YAML
Configure streaming inference via YAML as this example deployment:
build_id: "d4d56c1a-f326-40a0-88f3-f8e59c691a3e"
model_id: "stream-churn-model"
resources:
instance_size: "small"
pods: 2
stream:
consumer_bootstrap_server: "10.0.0.8"
consumer_topic: "model-input-topic"
producer_bootstrap_server: "10.0.0.9"
producer_topic: "model-output-topic"And then run using the below command:
qwak models deploy stream --from-file stream_deploy_config.yamlAdditionally, you can mix and match between command line arguments and configuration file. In this case, command line arguments will take precedence and override the values specified in the YAML file.
qwak models deploy stream --replicas 5 --from-file stream_deploy_config.yamlJFrog ML models run on Kubernetes, where we automatically install advanced production-grade monitoring tools.
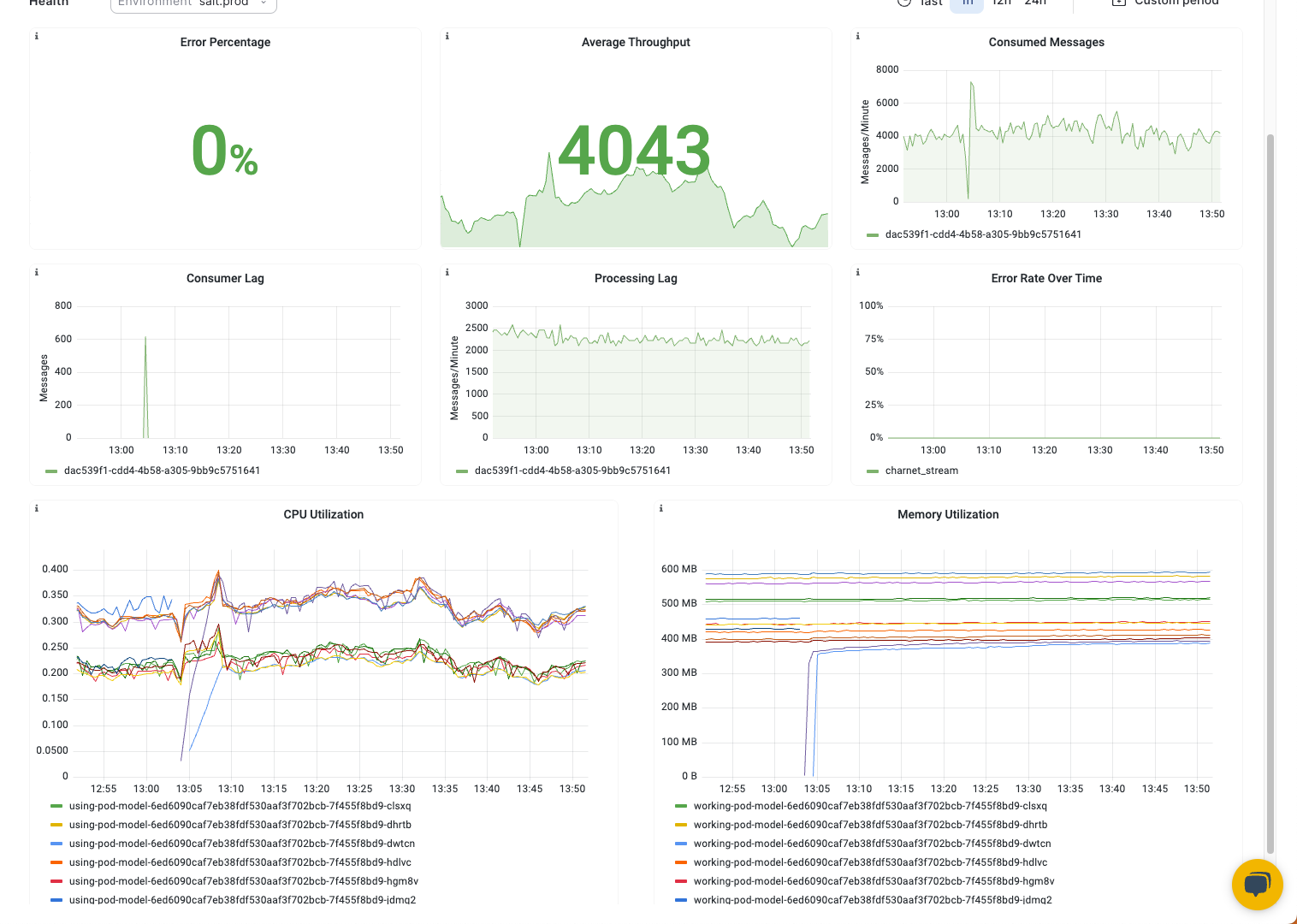
Under the Model Overview tab, you can view the following metrics for your deployed build:
- Average message throughput
- Total consumed messages
- Total produced messages
- Consumer lag
- Errors consuming messages
- Errors producing messages
- Memory, CPU and GPU utilization
Configuring streaming models
JFrog ML streaming deployments allow you to configure multiple consumer and producer specifications for a more granular control.
Consumer configuration
Consumer Bootstrap servers (Required)
Consumer Bootstrap servers (Required)A list of Kafka bootstrap server to consume messages for model inference.
Consumer Topic (Required)
Consumer Topic (Required)The Kafka topic to consume messages for model inference.
Consumer group (Required)
Consumer group (Required)The name of the consumer group the model inference is attached to.
Group ID
Group IDUsed to identify a group of consumers that belong to the same consumer group. Each message in a partition is delivered to only one consumer within the same group, enabling load balancing and parallel processing.
Auto offset reset (default: earliest)
Auto offset reset (default: earliest)Defines what happens when a consumer first joins a consumer group or when the consumer is unable to find a valid offset (e.g., because the offset doesn't exist or has been deleted). It determines whether the consumer should start reading messages from the earliest available offset ("earliest") or from the latest offset ("latest") in the topic.
Consumer timeout (default: 60000 ms)
Consumer timeout (default: 60000 ms)The maximum amount of time a consumer can be inactive before it is considered dead or no longer part of the consumer group. If a consumer does not send a heartbeat to Kafka within this timeout period, it may be removed from the group, and its partitions will be reassigned to other consumers.
Max batch (default: 1)
Max batch (default: 1)The maximum number of records the consumer will attempt to fetch in a single poll request to Kafka, which can affect throughput and latency.
Max polling latency (default: 1000 ms)
Max polling latency (default: 1000 ms)The maximum amount of time the consumer is willing to wait in a single poll request for new records to be available in the topic. If no new records are available within this time limit, the poll request will return empty.
Producer configuration
Producer Bootstrap servers (Required)
Producer Bootstrap servers (Required)A list of Kafka bootstrap server to produce model inference outputs.
Producer Topic (Required)
Producer Topic (Required)The Kafka topic to produce messages after model inference
Compression type (default: uncompressed)
Compression type (default: uncompressed)Determine how the messages sent by the producer are compressed before being stored in Kafka. Compressing messages can significantly reduce the amount of data transmitted over the network and storage requirements in Kafka. Kafka supports different compression types, and the producer can choose one of the following options
1. No Compression ("none")
Messages are not compressed at all. This option is suitable when message size is not a concern, and the data is already compressed or highly optimized.
2. Gzip Compression ("gzip")
Messages are compressed using the gzip algorithm. Gzip provides a good balance between compression ratio and processing overhead.
3. Snappy Compression ("snappy")
Messages are compressed using the Snappy compression algorithm. Snappy is faster than gzip but may not achieve the same compression ratio.
4. LZ4 Compression ("lz4")
Messages are compressed using the LZ4 compression algorithm. LZ4 is faster than both gzip and Snappy but may have a slightly lower compression ratio.
Custom Producer & Consumer Configurations
In a streaming inference deployment, you can customize Kafka consumer and producer configurations by adding environment variables. These environment variables should be prefixed with kafka.consumer for consumer attributes and kafka.producer for producer attributes.
To set these configurations, prepend the specific attribute from the Kafka configuration to the aforementioned prefixes. For example, to modify the bootstrap.servers configuration for a producer, use the environment variable kafka.producer.bootstrap.servers. The complete list of configurable attributes for Kafka consumers and producers is available in the Confluent Kafka Python SDK documentation. Ensure that the environment variables are correctly defined in your deployment configuration to facilitate proper communication with the Kafka infrastructure.
For example, in order to read from a Kafka topic where SASL authentication is required or enabled - you'll need SASL username and password combination and add them as environment variables to the streaming deployment. The full reference can be found here:
qwak models deploy stream --env-vars \
kafka.consumer.sasl.mechanism=PLAIN \
kafka.consumer.security_protocol=SASL_SSL \
kafka.consumer.sasl_plain_username=<username> \
kafka.consumer.sasl_plain_password=<password>
kafka.producer.sasl.mechanism=PLAIN \
kafka.producer.security_protocol=SASL_SSL \
kafka.producer.sasl_plain_username=<username> \
kafka.producer.sasl_plain_password=<password>Updated 7 months ago