
LLM Model Library
Deploy optimized and scalable open-source LLMs in one click
The JFrog ML LLM Model Library provides effortless deployment of optimized open-source models such as Llama 3, Mistral 7b, and more. Models can be deployed in just one click on your cloud or ours and automatically scale.
Coupled with our MLOps platform, feature store, vector store, and prompt management capabilities, the LLM model library allows you to deploy LLM applications to production in a single platform.
Deploying Open-Source LLMs
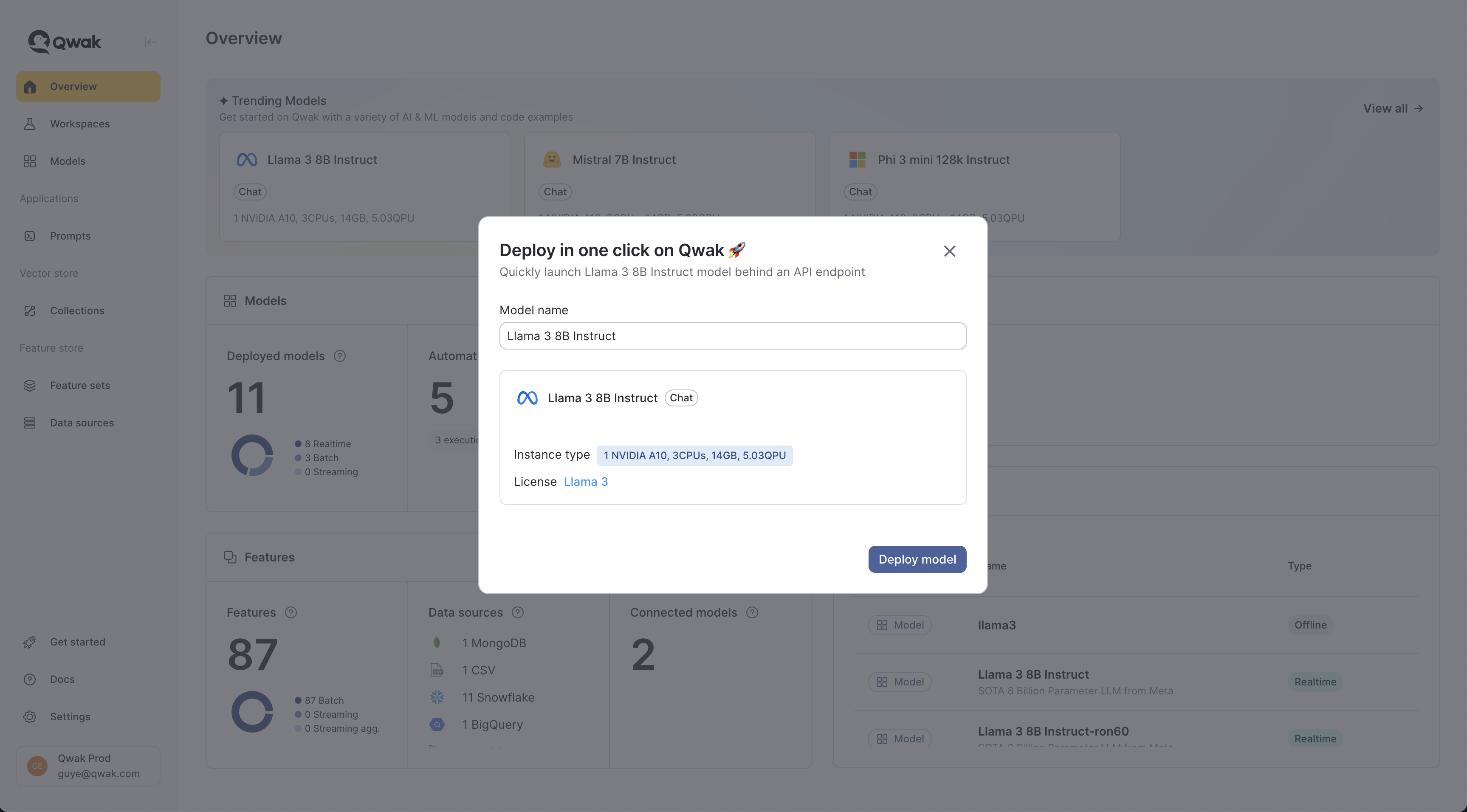
To deploy models from the model library, select a model and click deploy. JFrog ML handles all the rest for you. Model deployment would take several minutes, as we need to provision GPU instances and finalize the model deployment. Models are deployed on dedicated GPU instances for maximal performance and redundancy.
Your deployment details:
- Model name: A unique name which is immutable after deployment.
- Instance type: The instance on which the model is deployed. Can be modified once your model is live.
- License: A link to the official model license. Please notice the model license before using it.
Once your model is deployed, it will be available under the Model library project under the relevant model ID.
Using the OpenAI Client
LLMs on JFrog ML support the standard chat interface by OpenAI and can be easily accessed by either Python or REST API. Once your model is deployed you can switch to the Playground tab and see examples of model inference.
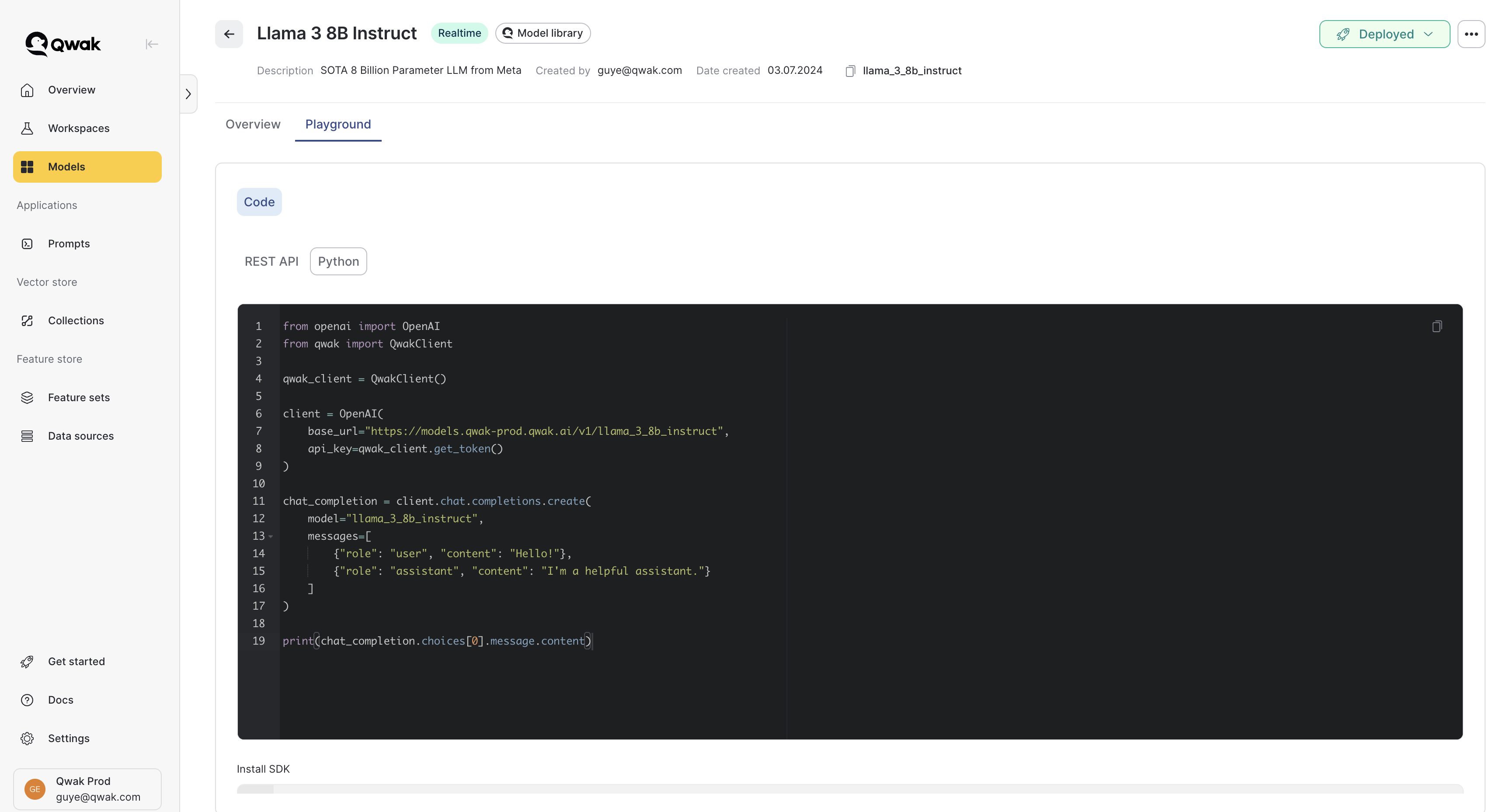
Using the Python Client
There are 3 simple steps to generate responses from models using the OpenAI Python client:
- Replace the
base_urlwith your specific model endpoint - Set the JFrog ML token as the
api_key, which can be generated using theQwakClient - Set the
modelparameter under the completion function to match your model ID
from openai import OpenAI
from qwak import QwakClient
qwak_client = QwakClient()
# Enter your model URL as the base URL
client = OpenAI(
base_url="https://models.qwak-prod.qwak.ai/v1/llama_3_8b_instruct", # Replace with your Qwak URL
api_key=qwak_client.get_token() # Qwak token
)
# Update the model ID to match the model ID on Qwak
chat_completion = client.chat.completions.create(
model="llama_3_8b_instruct", # Qwak model ID
messages=[
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "I'm a helpful assistant."}
]
)
print(chat_completion.choices[0].message.content)Please make sure to install the
qwak-sdkby following the Installation guide.
Using the REST Client
Models are also available via REST API following the Chat Completion API, and simply require an authentication token. The relevant steps are available in the Playground tab in the application, and also in the below section.
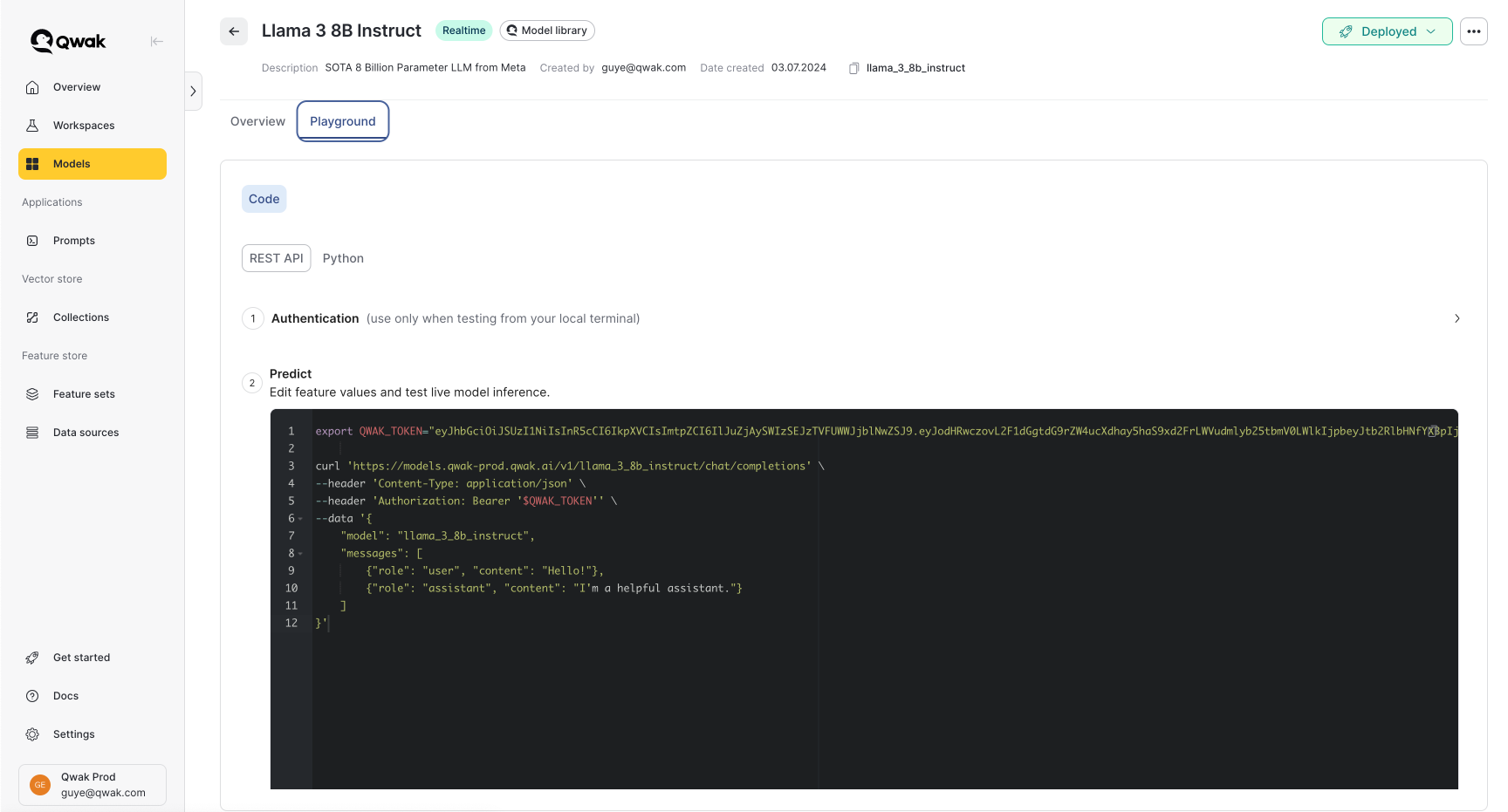
- Generate an authentication token using your JFrog ML API key.
curl --location --request POST 'https://grpc.qwak.ai/api/v1/authentication/qwak-api-key' \
--header 'Content-Type: application/json' \
--data '{"qwakApiKey": "${API_KEY}"}'- Use the authentication token to access the model for inference. Make sure to set the model ID both at the URL and in the request body.
export QWAK_TOKEN="<your-qwak-token>"
# Replace with your model URL
curl 'https://models.qwak-prod.qwak.ai/v1/llama_3_8b_instruct/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer '$QWAK_TOKEN'' \
--data '{
"model": "llama_3_8b_instruct",
"temperature": "1.2",
"max_tokens": "500",
"messages": [
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "I am a helpful assistant."}
]
}'Tracking Model Metrics
When deploying LLMs using the model library, we have four key metrics that help us track inference performance.
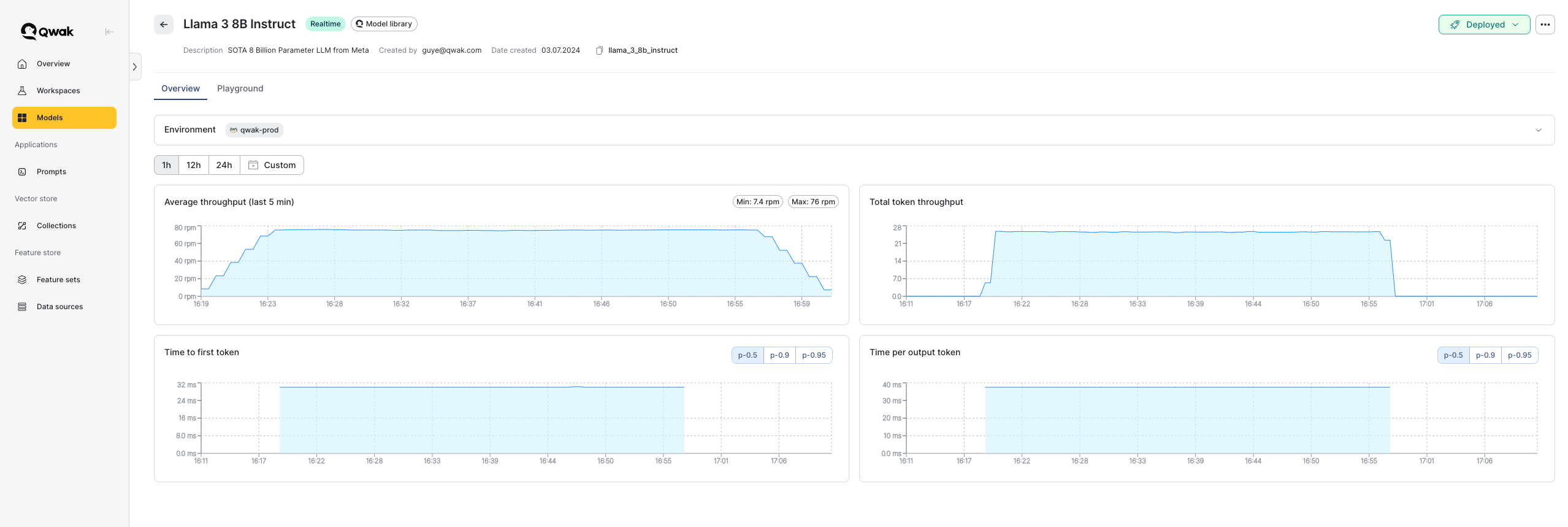
1. Average Throughput (Last 5 Minutes)
This metric represents the average number of requests the model has received in the last 5 minutes, measured in rpm (requests per minute).
2. Total Token Throughput
This metric shows the number of tokens generated per second by the model. It helps track how many tokens (completions) the model is producing.
3. Time to First Token
This metric measures the time it takes for the model to generate the first token after receiving a request.
4. Time per Output Token
This metric indicates the average time between the generation of each token by the model.
LangChain Support
You can easily use LangChain together with models from JFrog ML LLM model library. Since we use the standard chat API, all you need to do is replace the base url and provide the authentication token.
from qwak import QwakClient
from qwak.llmops.prompt.manager import PromptManager
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
prompt_name = "banker-agent" # A example prompt ID
prompt_manager = PromptManager()
# Fetch the prompt from Qwak
qwak_prompt = prompt_manager.get_prompt(
name=prompt_name
)
# Convert the Qwak prompt to a Langchain template
langchain_prompt = ChatPromptTemplate.from_messages(
qwak_prompt.prompt.template.to_messages()
)
qwak_client = QwakClient()
# Setup a LangChain LLM integration using the Qwak prompt configuration
# Configure the Qwak model ID and Qwak model URL
llm = ChatOpenAI(
model="llama_3_8b_instruct",
openai_api_base="https://models.qwak-prod.qwak.ai/v1/llama_3_8b_instruct",
openai_api_key=qwak_client.get_token(),
)
chain = langchain_prompt | llm
# Invoke the chain with an optional variable
response = chain.invoke({"question": "What's your name?"})
print(response)
Updated 7 months ago